




866
前言日常开发中,我们经常会遇到数据库慢查询。那么导致数据慢查询都有哪些常见的原因呢?今天田螺哥就跟大家聊聊导致MySQL慢查询的12个常见原因,以及对应的解决方法。一、SQL没加索引1、反例select * from user_info where name ='dbaplus社群' ;2、正例//添加索引alter table user_info add index idx_name (name);二、SQL 索引不生效有时候我们明明加了索引了,但是索引却不生效。在哪些场景,索引会不生效呢?主要有以下十大经典场景:1、隐式的类型转换,索引失效我们创建一个用户user表。CREATE TABLE user ( id int(11) NOT NULL AUTO_INCREMENT, userId varchar(32) NOT NULL, age varchar(16) NOT NULL, name varchar(255) NOT NULL, PRIMARY KEY (id), KEY idx_userid (userId) USING BTREE) ENGINE=InnoDB DEFAULT CHARSET=utf8;userId字段为字串类型,是B+树的普通索引,如果查询条件传了一个数字过去,会导致索引失效。如下:如果给数字加上'',也就是说,传的是一个字符串呢,当然是走索引,如下图:为什么第一条语句未加单引号就不走索引了呢?这是因为不加单引号时,是字符串跟数字的比较,它们类型不匹配,MySQL会做隐式的类型转换,把它们转换为浮点数再做比较。隐式的类型转换,索引会失效。2、查询条件包含or,可能导致索引失效我们还是用这个表结构:CREATE TABLE user ( id int(11) NOT NULL AUTO_INCREMENT, userId varchar(32) NOT NULL, age varchar(16) NOT NULL, name varchar(255) NOT NULL, PRIMARY KEY (id), KEY idx_userid (userId) USING BTREE) ENGINE=InnoDB DEFAULT CHARSET=utf8;其中userId加了索引,但是age没有加索引的。我们使用了or,以下SQL是不走索引的,如下:对于or+没有索引的age这种情况,假设它走了userId的索引,但是走到age查询条件时,它还得全表扫描,也就是需要三步过程:全表扫描+索引扫描+合并。如果它一开始就走全表扫描,直接一遍扫描就完事。Mysql优化器出于效率与成本考虑,遇到or条件,让索引失效,看起来也合情合理嘛。注意:如果or条件的列都加了索引,索引可能会走也可能不走,大家可以自己试一试哈。但是平时大家使用的时候,还是要注意一下这个or,学会用explain分析。遇到不走索引的时候,考虑拆开两条SQL。3、like通配符可能导致索引失效并不是用了like通配符,索引一定会失效,而是like查询是以%开头,才会导致索引失效。like查询以%开头,索引失效。explain select * from user where userId like '%123';把%放后面,发现索引还是正常走的,如下:explain select * from user where userId like '123%';既然like查询以%开头,会导致索引失效。我们如何优化呢?使用覆盖索引把%放后面4、查询条件不满足联合索引的最左匹配原则MySQl建立联合索引时,会遵循最左前缀匹配的原则,即最左优先。如果你建立一个(a,b,c)的联合索引,相当于建立了(a)、(a,b)、(a,b,c)三个索引。假设有以下表结构:CREATE TABLE user ( id int(11) NOT NULL AUTO_INCREMENT, user_id varchar(32) NOT NULL, age varchar(16) NOT NULL, name varchar(255) NOT NULL, PRIMARY KEY (id), KEY idx_userid_name (user_id,name) USING BTREE) ENGINE=InnoDB DEFAULT CHARSET=utf8;有一个联合索引idx_userid_name,我们执行这个SQL,查询条件是name,索引是无效:explain select * from user where name ='dbaplus社群';因为查询条件列name不是联合索引idx_userid_name中的第一个列,索引不生效在联合索引中,查询条件满足最左匹配原则时,索引才正常生效。5、在索引列上使用mysql的内置函数表结构:CREATE TABLE `user` ( `id` int(11) NOT NULL AUTO_INCREMENT, `userId` varchar(32) NOT NULL, `login_time` datetime NOT NULL, PRIMARY KEY (`id`), KEY `idx_userId` (`userId`) USING BTREE, KEY `idx_login_time` (`login_Time`) USING BTREE) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;虽然login_time加了索引,但是因为使用了mysql的内置函数Date_ADD(),索引直接GG,如图:一般这种情况怎么优化呢?可以把内置函数的逻辑转移到右边,如下:explain select * from user where login_time = DATE_ADD('2022-05-22 00:00:00',INTERVAL -1 DAY);6、对索引进行列运算(如,+、-、*、/),索引不生效表结构:CREATE TABLE `user` ( `id` int(11) NOT NULL AUTO_INCREMENT, `userId` varchar(32) NOT NULL, `age` int(11) DEFAULT NULL, PRIMARY KEY (`id`), KEY `idx_age` (`age`) USING BTREE) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;虽然age加了索引,但是因为它进行运算,索引直接迷路了。如图:所以不可以对索引列进行运算,可以在代码处理好,再传参进去。7、索引字段上使用(!= 或者 < >),索引可能失效表结构:CREATE TABLE `user` ( `id` int(11) NOT NULL AUTO_INCREMENT, `userId` int(11) NOT NULL, `age` int(11) DEFAULT NULL, `name` varchar(255) NOT NULL, PRIMARY KEY (`id`), KEY `idx_age` (`age`) USING BTREE) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;虽然age加了索引,但是使用了!= 或者< >,not in这些时,索引如同虚设。如下:其实这个也是跟mySQL优化器有关,如果优化器觉得即使走了索引,还是需要扫描很多很多行的哈,它觉得不划算,不如直接不走索引。平时我们用!= 或者< >,not in的时候,留点心眼哈。8、索引字段上使用is null, is not null,索引可能失效表结构:CREATE TABLE `user` ( `id` int(11) NOT NULL AUTO_INCREMENT, `card` varchar(255) DEFAULT NULL, `name` varchar(255) DEFAULT NULL, PRIMARY KEY (`id`), KEY `idx_name` (`name`) USING BTREE, KEY `idx_card` (`card`) USING BTREE) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;单个name字段加上索引,并查询name为非空的语句,其实会走索引的,如下:单个card字段加上索引,并查询name为非空的语句,其实会走索引的,如下:但是它两用or连接起来,索引就失效了,如下:很多时候,也是因为数据量问题,导致了MySQL优化器放弃走索引。同时,平时我们用explain分析SQL的时候,如果type=range,要注意一下哈,因为这个可能因为数据量问题,导致索引无效。9、左右连接,关联的字段编码格式不一样新建两个表,一个user,一个user_job:CREATE TABLE `user` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(255) CHARACTER SET utf8mb4 DEFAULT NULL, `age` int(11) NOT NULL, PRIMARY KEY (`id`), KEY `idx_name` (`name`) USING BTREE) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;CREATE TABLE `user_job` ( `id` int(11) NOT NULL, `userId` int(11) NOT NULL, `job` varchar(255) DEFAULT NULL, `name` varchar(255) DEFAULT NULL, PRIMARY KEY (`id`), KEY `idx_name` (`name`) USING BTREE) ENGINE=InnoDB DEFAULT CHARSET=utf8;user表的name字段编码是utf8mb4,而user_job表的name字段编码为utf8。执行左外连接查询,user_job表还是走全表扫描,如下:如果把它们的name字段改为编码一致,相同的SQL,还是会走索引。所以大家在做表关联时,注意一下关联字段的编码问题哈。10、优化器选错了索引MySQL 中一张表是可以支持多个索引的。你写SQL语句的时候,没有主动指定使用哪个索引的话,用哪个索引是由MySQL来确定的。我们日常开发中,不断地删除历史数据和新增数据的场景,有可能会导致MySQL选错索引。那么有哪些解决方案呢?使用force index 强行选择某个索引;修改你的SQl,引导它使用我们期望的索引;优化你的业务逻辑;优化你的索引,新建一个更合适的索引,或者删除误用的索引。三、limit深分页问题limit深分页问题,会导致慢查询,应该大家都司空见惯了吧。1、limit深分页为什么会变慢limit深分页为什么会导致SQL变慢呢?假设我们有表结构如下:CREATE TABLE account ( id int(11) NOT NULL AUTO_INCREMENT COMMENT '主键Id', name varchar(255) DEFAULT NULL COMMENT '账户名', balance int(11) DEFAULT NULL COMMENT '余额', create_time datetime NOT NULL COMMENT '创建时间', update_time datetime NOT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间', PRIMARY KEY (id), KEY idx_name (name), KEY idx_create_time (create_time) //索引) ENGINE=InnoDB AUTO_INCREMENT=1570068 DEFAULT CHARSET=utf8 ROW_FORMAT=REDUNDANT COMMENT='账户表';你知道以下SQL,执行过程是怎样的嘛?select id,name,balance from account where create_time> '2020-09-19' limit 100000,10;这个SQL的执行流程:通过普通二级索引树idx_create_time,过滤create_time条件,找到满足条件的主键id。通过主键id,回到id主键索引树,找到满足记录的行,然后取出需要展示的列(回表过程)。扫描满足条件的100010行,然后扔掉前100000行,返回。limit深分页,导致SQL变慢原因有两个:limit语句会先扫描offset+n行,然后再丢弃掉前offset行,返回后n行数据。也就是说limit 100000,10,就会扫描100010行,而limit 0,10,只扫描10行。limit 100000,10 扫描更多的行数,也意味着回表更多的次数。2、如何优化深分页问题我们可以通过减少回表次数来优化。一般有标签记录法和延迟关联法。1)标签记录法就是标记一下上次查询到哪一条了,下次再来查的时候,从该条开始往下扫描。就好像看书一样,上次看到哪里了,你就折叠一下或者夹个书签,下次来看的时候,直接就翻到。假设上一次记录到100000,则SQL可以修改为:select id,name,balance FROM account where id > 100000 limit 10;这样的话,后面无论翻多少页,性能都会不错的,因为命中了id索引。但是这种方式有局限性:需要一种类似连续自增的字段。2)延迟关联法延迟关联法,就是把条件转移到主键索引树,然后减少回表。如下:select acct1.id,acct1.name,acct1.balance FROM account acct1 INNER JOIN (SELECT a.id FROM account a WHERE a.create_time > '2020-09-19' limit 100000, 10) AS acct2 on acct1.id= acct2.id;优化思路就是,先通过idx_create_time二级索引树查询到满足条件的主键ID,再与原表通过主键ID内连接,这样后面直接走了主键索引了,同时也减少了回表。四、单表数据量太大1、单表数据量太大为什么会变慢?一个表的数据量达到好几千万或者上亿时,加索引的效果没那么明显啦。性能之所以会变差,是因为维护索引的B+树结构层级变得更高了,查询一条数据时,需要经历的磁盘IO变多,因此查询性能变慢。2、一棵B+树可以存多少数据量大家是否还记得,一个B+树大概可以存放多少数据量呢?InnoDB存储引擎最小储存单元是页,一页大小就是16k。B+树叶子存的是数据,内部节点存的是键值+指针。索引组织表通过非叶子节点的二分查找法以及指针确定数据在哪个页中,进而再去数据页中找到需要的数据;假设B+树的高度为2的话,即有一个根结点和若干个叶子结点。这棵B+树的存放总记录数为=根结点指针数*单个叶子节点记录行数。如果一行记录的数据大小为1k,那么单个叶子节点可以存的记录数 =16k/1k =16。非叶子节点内存放多少指针呢?我们假设主键ID为bigint类型,长度为8字节(面试官问你int类型,一个int就是32位,4字节),而指针大小在InnoDB源码中设置为6字节,所以就是8+6=14字节,16k/14B =16*1024B/14B = 1170。因此,一棵高度为2的B+树,能存放1170 * 16=18720条这样的数据记录。同理一棵高度为3的B+树,能存放1170 *1170 *16 =21902400,也就是说,可以存放两千万左右的记录。B+树高度一般为1-3层,已经满足千万级别的数据存储。如果B+树想存储更多的数据,那树结构层级就会更高,查询一条数据时,需要经历的磁盘IO变多,因此查询性能变慢。3、如何解决单表数据量太大,查询变慢的问题一般超过千万级别,我们可以考虑分库分表了。分库分表可能导致的问题:事务问题跨库问题排序问题分页问题分布式ID因此,大家在评估是否分库分表前,先考虑下,是否可以把部分历史数据归档先,如果可以的话,先不要急着分库分表。如果真的要分库分表,综合考虑和评估方案。比如可以考虑垂直、水平分库分表。水平分库分表策略的话,range范围、hash取模、range+hash取模混合等等。 五、join 或者子查询过多一般来说,不建议使用子查询,可以把子查询改成join来优化。而数据库有个规范约定就是:尽量不要有超过3个以上的表连接。为什么要这么建议呢? 我们来聊聊,join哪些方面可能导致慢查询吧。MySQL中,join的执行算法,分别是:Index Nested-Loop Join和Block Nested-Loop Join。Index Nested-Loop Join:这个join算法,跟我们写程序时的嵌套查询类似,并且可以用上被驱动表的索引。Block Nested-Loop Join:这种join算法,被驱动表上没有可用的索引,它会先把驱动表的数据读入线程内存join_buffer中,再扫描被驱动表,把被驱动表的每一行取出来,跟join_buffer中的数据做对比,满足join条件的,作为结果集的一部分返回。join过多的问题:一方面,过多的表连接,会大大增加SQL复杂度。另外一方面,如果可以使用被驱动表的索引那还好,并且使用小表来做驱动表,查询效率更佳。如果被驱动表没有可用的索引,join是在join_buffer内存做的,如果匹配的数据量比较小或者join_buffer设置的比较大,速度也不会太慢。但是,如果join的数据量比较大时,mysql会采用在硬盘上创建临时表的方式进行多张表的关联匹配,这种显然效率就极低,本来磁盘的 IO 就不快,还要关联。一般情况下,如果业务需要的话,关联2~3个表是可以接受的,但是关联的字段需要加索引哈。如果需要关联更多的表,建议从代码层面进行拆分,在业务层先查询一张表的数据,然后以关联字段作为条件查询关联表形成map,然后在业务层进行数据的拼装。六、in元素过多如果使用了in,即使后面的条件加了索引,还是要注意in后面的元素不要过多哈。in元素一般建议不要超过500个,如果超过了,建议分组,每次500一组进行哈。1、反例select user_id,name from user where user_id in (1,2,3...1000000); 如果我们对in的条件不做任何限制的话,该查询语句一次性可能会查询出非常多的数据,很容易导致接口超时。尤其有时候,我们是用的子查询,in后面的子查询,你都不知道数量有多少那种,更容易采坑(所以我把in元素过多抽出来作为一个小节)。如下这种子查询:select * from user where user_id in (select author_id from artilce where type = 1);2、正例分批进行,每批500个:select user_id,name from user where user_id in (1,2,3...500);如果传参的ids太多,还可以做个参数校验什么的:if (userIds.size() > 500) { throw new Exception("单次查询的用户Id不能超过200");}七、数据库在刷脏页1、什么是脏页当内存数据页跟磁盘数据页内容不一致的时候,我们称这个内存页为“脏页”。内存数据写入到磁盘后,内存和磁盘上的数据页的内容就一致了,称为“干净页”。一般有更新SQL才可能会导致脏页,我们回忆一下:一条更新语句是如何执行的。2、一条更新语句是如何执行的?以下的这个更新SQL,如何执行的呢?update t set c=c+1 where id=666;对于这条更新SQL,执行器会先找引擎取id=666这一行。如果这行所在的数据页本来就在内存中的话,就直接返回给执行器。如果不在内存,就去磁盘读入内存,再返回。执行器拿到引擎给的行数据后,给这一行C的值加一,得到新的一行数据,再调用引擎接口写入这行新数据。引擎将这行新数据更新到内存中,同时将这个更新操作记录到redo log里面,但是此时redo log 是处于prepare状态的哈。执行器生成这个操作的binlog,并把binlog写入磁盘。执行器调用引擎的提交事务接口,引擎把刚刚写入的redo log改成提交(commit)状态,更新完成。InnoDB 在处理更新语句的时候,只做了写日志这一个磁盘操作。这个日志叫作redo log(重做日志)。平时更新SQL执行得很快,其实是因为它只是在写内存和redo log日志,等到空闲的时候,才把redo log日志里的数据同步到磁盘中。有些小伙伴可能有疑惑,redo log日志不是在磁盘嘛?那为什么不慢?其实是因为写redo log的过程是顺序写磁盘的。磁盘顺序写会减少寻道等待时间,速度比随机写要快很多的。3、为什么会出现脏页呢?更新SQL只是在写内存和redo log日志,等到空闲的时候,才把redo log日志里的数据同步到磁盘中。这时内存数据页跟磁盘数据页内容不一致,就出现脏页。4、什么时候会刷脏页(flush)?InnoDB存储引擎的redo log大小是固定,且是环型写入的,如下图(图片来源于MySQL 实战 45 讲):那什么时候会刷脏页?有几种场景:redo log写满了,要刷脏页。这种情况要尽量避免的。因为出现这种情况时,整个系统就不能再接受更新啦,即所有的更新都必须堵住。内存不够了,需要新的内存页,就要淘汰一些数据页,这时候会刷脏页。InnoDB 用缓冲池(buffer pool)管理内存,而当要读入的数据页没有在内存的时候,就必须到缓冲池中申请一个数据页。这时候只能把最久不使用的数据页从内存中淘汰掉:如果要淘汰的是一个干净页,就直接释放出来复用;但如果是脏页呢,就必须将脏页先刷到磁盘,变成干净页后才能复用。MySQL 认为系统空闲的时候,也会刷一些脏页。MySQL 正常关闭时,会把内存的脏页都 flush 到磁盘上。5、为什么刷脏页会导致SQL变慢呢?redo log写满了,要刷脏页,这时候会导致系统所有的更新堵住,写性能都跌为0了,肯定慢呀。一般要杜绝出现这个情况。一个查询要淘汰的脏页个数太多,一样会导致查询的响应时间明显变长。八、order by 文件排序order by就一定会导致慢查询吗?不是这样的哈,因为order by平时用得多,并且数据量一上来,还是走文件排序的话,很容易有慢SQL的。听我娓娓道来,order by哪些时候可能会导致慢SQL哈。1、order by 的 Using filesort文件排序我们平时经常需要用到order by ,主要就是用来给某些字段排序的。比如以下SQL:select name,age,city from staff where city = '深圳' order by age limit 10;它表示的意思就是:查询前10个,来自深圳员工的姓名、年龄、城市,并且按照年龄小到大排序。查看explain执行计划的时候,可以看到Extra这一列,有一个Using filesort,它表示用到文件排序。2、order by文件排序效率为什么较低order by用到文件排序时,为什么查询效率会相对低呢?order by排序,分为全字段排序和rowid排序。它是拿max_length_for_sort_data和结果行数据长度对比,如果结果行数据长度超过max_length_for_sort_data这个值,就会走rowid排序,相反,则走全字段排序。1)rowid排序rowid排序,一般需要回表去找满足条件的数据,所以效率会慢一点。以下这个SQL,使用rowid排序,执行过程是这样:select name,age,city from staff where city = '深圳' order by age limit 10;MySQL 为对应的线程初始化sort_buffer,放入需要排序的age字段,以及主键id;从索引树idx_city, 找到第一个满足 city='深圳’条件的主键id,也就是图中的id=9;到主键id索引树拿到id=9的这一行数据, 取age和主键id的值,存到sort_buffer;从索引树idx_city拿到下一个记录的主键id,即图中的id=13;重复步骤 3、4 直到city的值不等于深圳为止;前面5步已经查找到了所有city为深圳的数据,在sort_buffer中,将所有数据根据age进行排序;遍历排序结果,取前10行,并按照id的值回到原表中,取出city、name 和 age三个字段返回给客户端。2)全字段排序同样的SQL,如果是走全字段排序是这样的:select name,age,city from staff where city = '深圳' order by age limit 10;MySQL 为对应的线程初始化sort_buffer,放入需要查询的name、age、city字段;从索引树idx_city, 找到第一个满足 city='深圳’条件的主键 id,也就是图中的id=9;到主键id索引树拿到id=9的这一行数据, 取name、age、city三个字段的值,存到sort_buffer;从索引树idx_city 拿到下一个记录的主键id,即图中的id=13;重复步骤 3、4 直到city的值不等于深圳为止;前面5步已经查找到了所有city为深圳的数据,在sort_buffer中,将所有数据根据age进行排序;按照排序结果取前10行返回给客户端。sort_buffer的大小是由一个参数控制的:sort_buffer_size。如果要排序的数据小于sort_buffer_size,排序在sort_buffer内存中完成。如果要排序的数据大于sort_buffer_size,则借助磁盘文件来进行排序。借助磁盘文件排序的话,效率就更慢一点。因为先把数据放入sort_buffer,当快要满时。会排一下序,然后把sort_buffer中的数据,放到临时磁盘文件,等到所有满足条件数据都查完排完,再用归并算法把磁盘的临时排好序的小文件,合并成一个有序的大文件。3、如何优化order by的文件排序order by使用文件排序,效率会低一点。我们怎么优化呢?因为数据是无序的,所以就需要排序。如果数据本身是有序的,那就不会再用到文件排序啦。而索引数据本身是有序的,我们通过建立索引来优化order by语句。我们还可以通过调整max_length_for_sort_data、sort_buffer_size等参数优化。九、拿不到锁有时候,我们查询一条很简单的SQL,但是却等待很长的时间,不见结果返回。一般这种时候就是表被锁住了,或者要查询的某一行或者几行被锁住了。我们只能慢慢等待锁被释放。举一个生活的例子哈,你和别人合租了一间房子,这个房子只有一个卫生间的话。假设某一时刻,你们都想去卫生间,但是对方比你早了一点点。那么此时你只能等对方出来后才能进去。这时候,我们可以用show processlist命令,看看当前语句处于什么状态哈。十、delete + in子查询不走索引之前见到过一个生产慢SQL问题,当delete遇到in子查询时,即使有索引,也是不走索引的。而对应的select + in子查询,却可以走索引。MySQL版本是5.7,假设当前有两张表account和old_account,表结构如下:CREATE TABLE `old_account` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键Id', `name` varchar(255) DEFAULT NULL COMMENT '账户名', `balance` int(11) DEFAULT NULL COMMENT '余额', `create_time` datetime NOT NULL COMMENT '创建时间', `update_time` datetime NOT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间', PRIMARY KEY (`id`), KEY `idx_name` (`name`) USING BTREE) ENGINE=InnoDB AUTO_INCREMENT=1570068 DEFAULT CHARSET=utf8 ROW_FORMAT=REDUNDANT COMMENT='老的账户表';CREATE TABLE `account` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键Id', `name` varchar(255) DEFAULT NULL COMMENT '账户名', `balance` int(11) DEFAULT NULL COMMENT '余额', `create_time` datetime NOT NULL COMMENT '创建时间', `update_time` datetime NOT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间', PRIMARY KEY (`id`), KEY `idx_name` (`name`) USING BTREE) ENGINE=InnoDB AUTO_INCREMENT=1570068 DEFAULT CHARSET=utf8 ROW_FORMAT=REDUNDANT COMMENT='账户表';执行的SQL如下:delete from account where name in (select name from old_account);查看执行计划,发现不走索引:但是如果把delete换成select,就会走索引。如下:为什么select + in子查询会走索引,delete + in子查询却不会走索引呢?我们执行以下SQL看看:explain select * from account where name in (select name from old_account);show WARNINGS; //可以查看优化后,最终执行的sql结果如下:select `test2`.`account`.`id` AS `id`,`test2`.`account`.`name` AS `name`,`test2`.`account`.`balance` AS `balance`,`test2`.`account`.`create_time` AS `create_time`,`test2`.`account`.`update_time` AS `update_time` from `test2`.`account` semi join (`test2`.`old_account`)where (`test2`.`account`.`name` = `test2`.`old_account`.`name`)可以发现,实际执行的时候,MySQL对select in子查询做了优化,把子查询改成join的方式,所以可以走索引。但是很遗憾,对于delete in子查询,MySQL却没有对它做这个优化。日常开发中,大家注意一下这个场景。十一、group by使用临时表group by一般用于分组统计,它表达的逻辑就是根据一定的规则,进行分组。日常开发中,我们使用得比较频繁。如果不注意,很容易产生慢SQL。1、group by的执行流程假设有表结构:CREATE TABLE `staff` ( `id` bigint(11) NOT NULL AUTO_INCREMENT COMMENT '主键id', `id_card` varchar(20) NOT NULL COMMENT '身份证号码', `name` varchar(64) NOT NULL COMMENT '姓名', `age` int(4) NOT NULL COMMENT '年龄', `city` varchar(64) NOT NULL COMMENT '城市', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=15 DEFAULT CHARSET=utf8 COMMENT='员工表';我们查看一下这个SQL的执行计划:explain select city ,count(*) as num from staff group by city;Extra 这个字段的Using temporary表示在执行分组的时候使用了临时表。Extra 这个字段的Using filesort表示使用了文件排序。group by是怎么使用到临时表和排序了呢?我们来看下这个SQL的执行流程:select city ,count(*) as num from staff group by city;1)创建内存临时表,表里有两个字段city和num;2)全表扫描staff的记录,依次取出city = 'X'的记录。判断临时表中是否有为 city='X'的行,没有就插入一个记录 (X,1);如果临时表中有city='X'的行,就将X这一行的num值加 1;3)遍历完成后,再根据字段city做排序,得到结果集返回给客户端。这个流程的执行图如下:临时表的排序是怎样的呢?就是把需要排序的字段,放到sort buffer,排完就返回。在这里注意一点哈,排序分全字段排序和rowid排序。如果是全字段排序,需要查询返回的字段,都放入sort buffer,根据排序字段排完,直接返回。如果是rowid排序,只是需要排序的字段放入sort buffer,然后多一次回表操作,再返回。2、group by可能会慢在哪里?group by使用不当,很容易就会产生慢SQL 问题。因为它既用到临时表,又默认用到排序。有时候还可能用到磁盘临时表。如果执行过程中,会发现内存临时表大小到达了上限(控制这个上限的参数就是tmp_table_size),会把内存临时表转成磁盘临时表。如果数据量很大,很可能这个查询需要的磁盘临时表,就会占用大量的磁盘空间。3、如何优化group by呢?从哪些方向去优化呢?方向1:既然它默认会排序,我们不给它排是不是就行啦。方向2:既然临时表是影响group by性能的X因素,我们是不是可以不用临时表?我们一起来想下,执行group by语句为什么需要临时表呢?group by的语义逻辑,就是统计不同的值出现的个数。如果这个这些值一开始就是有序的,我们是不是直接往下扫描统计就好了,就不用临时表来记录并统计结果啦?可以有这些优化方案:group by 后面的字段加索引order by null 不用排序尽量只使用内存临时表使用SQL_BIG_RESULT十二、系统硬件或网络资源如果数据库服务器内存、硬件资源,或者网络资源配置不是很好,就会慢一些哈。这时候可以升级配置。这就好比你的计算机有时候很卡,你可以加个内存条什么的一个道理。如果数据库压力本身很大,比如高并发场景下,大量请求到数据库来,数据库服务器CPU占用很高或者IO利用率很高,这种情况下所有语句的执行都有可能变慢的哈。最后如果测试环境数据库的一些参数配置,和生产环境参数配置不一致的话,也容易产生慢SQL哈。之前见过一个慢SQL的生产案例,就是测试环境用了index merge,所以查看explain执行计划时,是可以走索引的,但是到了生产,却全表扫描,最后排查发现是生产环境配置把index merge关闭了。
0
0 675天前
1097
我们平时建表的时候,一般会像下面这样。CREATE TABLE `user` ( `id` int NOT NULL AUTO_INCREMENT COMMENT '主键', `name` char(10) NOT NULL DEFAULT '' COMMENT '名字', PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;出于习惯,我们一般会加一列id作为主键,而这个主键一般边上都有个AUTO_INCREMENT, 意思是这个主键是自增的。自增就是i++,也就是每次都加1。但问题来了。主键id不自增行不行?为什么要用自增id做主键?离谱点,没有主键可以吗?什么情况下不应该自增?被这么一波追问,念头都不通达了?这篇文章,我会尝试回答这几个问题。主键不自增行不行当然是可以的。比如我们可以把建表sql里的AUTO_INCREMENT去掉。CREATE TABLE `user` ( `id` int NOT NULL COMMENT '主键', `name` char(10) NOT NULL DEFAULT '' COMMENT '名字', PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;然后执行INSERT INTO `user` (`name`) VALUES ('debug');这时候会报错Field 'id' doesn't have a default value。也就是说如果你不让主键自增的话,那你在写数据的时候需要自己指定id的值是多少,想要主键id是多少就写多少进去,不写就报错。改成下面这样就好了INSERT INTO `user` (`id`,`name`) VALUES (10, 'debug');为什么要用自增主键我们在数据库里保存的数据就跟excel表一样,一行行似的。user表而在底层,这一行行数据,就是保存在一个个16k大小的页里。每次都去遍历所有的行性能会不好,于是为了加速搜索,我们可以根据主键id,从小到大排列这些行数据,将这些数据页用双向链表的形式组织起来,再将这些页里的部分信息提取出来放到一个新的16kb的数据页里,再加入层级的概念。于是,一个个数据页就被组织起来了,成为了一棵B+树索引。B+树结构而当我们在建表sql里声明了PRIMARY KEY (id)时,mysql的innodb引擎,就会为主键id生成一个主键索引,里面就是通过B+树的形式来维护这套索引。到这里,我们有两个点是需要关注的:数据页大小是固定16k数据页内,以及数据页之间,数据主键id都是从小到大排序的由于数据页大小固定了是16k,当我们需要插入一条新的数据,数据页会被慢慢放满,当超过16k时,这个数据页就有可能会进行分裂。针对B+树叶子节点,如果主键是自增的,那它产生的id每次都比前一次要大,所以每次都会将数据加在B+树尾部,B+树的叶子节点本质上是双向链表,查找它的首部和尾部,时间复杂度O(1)。而如果此时最末尾的数据页满了,那创建个新的页就好。主键id自增的情况如果主键不是自增的,比方说上次分配了id=7,这次分配了id=3,为了让新加入数据后B+树的叶子节点还能保持有序,它就需要往叶子结点的中间找,查找过程的时间复杂度是O(lgn),如果这个页正好也满了,这时候就需要进行页分裂了。并且页分裂操作本身是需要加悲观锁的。总体看下来,自增的主键遇到页分裂的可能性更少,因此性能也会更高。主键id不自增的情况没有主键可以吗mysql表如果没有主键索引,查个数据都得全表扫描,那既然它这么重要,我今天就不当人了,不声明主键,可以吗?嗯,你完全可以不声明主键。你确实可以在建表sql里写成这样。CREATE TABLE `user` ( `name` char(10) NOT NULL DEFAULT '' COMMENT '名字') ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;看起来确实是没有主键的样子。然而实际上,mysql的innodb引擎内部会帮你生成一个名为ROW_ID列,它是个6字节的隐藏列,你平时也看不到它,但实际上,它也是自增的。有了这层兜底机制保证,数据表肯定会有主键和主键索引。跟ROW_ID被隐藏的列还有trx_id字段,用于记录当前这一行数据行是被哪个事务修改的,和一个roll_pointer字段,这个字段是用来指向当前这个数据行的上一个版本,通过这个字段,可以为这行数据形成一条版本链,从而实现多版本并发控制(MVCC)。有没有很眼熟,这个在之前写的文章里出现过。隐藏的row_id列有没有建议主键不自增的场景前面提到了主键自增可以带来很多好处,事实上大部分场景下,我们都建议主键设为自增。那有没有不建议主键自增的场景呢?mysql分库分表下的id聊到分库分表,那我就需要说明下,递增和自增的区别了,自增就是每次都+1,而递增则是新的id比上一个id要大就行了,具体大多少,没关系。之前写过一篇文章提到过,mysql在水平分库分表时,一般有两种方式。一种分表方式是通过对id取模进行分表,这种要求递增就好,不要求严格自增,因为取模后数据会被分散到多个分表中,就算id是严格自增的,在分散之后,都只能保证每个分表里id只能是递增的。根据id取模分表另一种分表方式是根据id的范围进行分表(分片),它会划出一定的范围,比如以2kw为一个分表的大小,那0~2kw就放在这张分表中,2kw~4kw放在另一张分表中,数据不断增加,分表也可以不断增加,非常适合动态扩容,但它要求id自增,如果id递增,数据则会出现大量空洞。举个例子,比如第一次分配id=2,第二次分配id=2kw,这时候第一张表的范围就被打满了,后面再分配一个id,比如是3kw,就只能存到2kw~4kw(第二张)的分表中。那我在0~2kw这个范围的分表,也就存了两条数据,这太浪费了。根据id范围分表但不管哪种分表方式,一般是不可能继续用原来表里的自增主键的,原因也比较好理解,原来的每个表如果都从0开始自增的话,那好几个表就会出现好几次重复的id,根据id唯一的原则,这显然不合理。所以我们在分库分表的场景下,插入的id都是专门的id服务生成的,如果是要严格自增的话,那一般会通过redis来获得,当然不会是一个id请求获取一次,一般会按批次去获得,比如一次性获得100个。快用完了再去获取下一批100个。但这个方案有个问题,它严重依赖redis,如果redis挂了,那整个功能就傻了。有没有不依赖于其他第三方组件的方法呢?雪花算法有,比如Twitter开源的雪花算法。雪花算法通过64位有特殊含义的数字来组成id。雪花算法首先第0位不用。接下来的41位是时间戳。精度是毫秒,这个大小大概能表示个69年左右,因为时间戳随着时间流逝肯定是越来越大的,所以这部分决定了生成的id肯定是越来越大的。再接下来的10位是指产生这些雪花算法的工作机器id,这样就可以让每个机器产生的id都具有相应的标识。再接下来的12位,序列号,就是指这个工作机器里生成的递增数字。可以看出,只要处于同一毫秒内,所有的雪花算法id的前42位的值都是一样的,因此在这一毫秒内,能产生的id数量就是 2的10次方✖️2的12次方,大概400w,肯定是够用了,甚至有点多了。但是!细心的兄弟们肯定也发现了,雪花算法它算出的数字动不动就比上次的数字多个几百几万的,也就是它生成的id是趋势递增的,并不是严格+1自增的,也就是说它并不太适合于根据范围来分表的场景。这是个非常疼的问题。还有个小问题是,那10位工作机器id,我每次扩容一个工作机器,这个机器怎么知道自己的id是多少呢?是不是得从某个地方读过来。那有没有一种生成id生成方案,既能让分库分表能做到很好的支持动态扩容,又能像雪花算法那样并不依赖redis这样的第三方服务。有。这就是这篇文章的重点了。适合分库分表的uuid算法我们可以参考雪花算法的实现,设计成下面这样。注意下面的每一位,都是十进制,而不是二进制。适合分库分表的uuid算法开头的12位依然是时间,但并不是时间戳,雪花算法的时间戳精确到毫秒,我们用不上这么细,我们改为yyMMddHHmmss,注意开头的yy是两位,也就是这个方案能保证到2099年之前,id都不会重复,能用到重复,那也是真·百年企业。同样由于最前面是时间,随着时间流逝,也能保证id趋势递增。接下来的10位,用十进制的方式表示工作机器的ip,就可以把12位的ip转为10位的数字,它可以保证全局唯一,只要服务起来了,也就知道自己的ip是多少了,不需要像雪花算法那样从别的地方去读取worker id了,又是一个小细节。在接下来的6位,就用于生成序列号,它能支持每秒钟生成100w个id。最后的4位,也是这个id算法最妙的部分。它前2位代表分库id,后2位代表分表id。也就是支持一共100*100=1w张分表。举个例子,假设我只用了1个分库,当我一开始只有3张分表的情况下,那我可以通过配置,要求生成的uuid最后面的2位,取值只能是[0,1,2],分别对应三个表。这样我生成出来的id,就能非常均匀的落到三个分表中,这还顺带解决了单个分表热点写入的问题。如果随着业务不断发展,需要新加入两张新的表(3和4),同时第0张表有点满了,不希望再被写了,那就将配置改为[1,2,3,4],这样生成的id就不会再插入到对应的0表中。同时还可以加入生成id的概率和权重来调整哪个分表落更多数据。有了这个新的uuid方案,我们既可以保证生成的数据趋势递增,同时也能非常方便扩展分表。非常nice。数据库有那么多种,mysql只是其中一种,那其他数据库也是要求主键自增吗?tidb的主键id不建议自增tidb是一款分布式数据库,作为mysql分库分表场景下的替代产品,可以更好的对数据进行分片。它通过引入Range的概念进行数据表分片,比如第一个分片表的id在0~2kw,第二个分片表的id在2kw~4kw。这其实就是根据id范围进行数据库分表。它的语法几乎跟mysql一致,用起来大部分时候是无感的。但跟mysql有一点很不一样的就是,mysql建议id自增,但tidb却建议使用随机的uuid。原因是如果id自增的话,根据范围分片的规则,一段时间内生成的id几乎都会落到同一个分片上,比如下图,从3kw开始的自增uuid,几乎都落到range 1这个分片中,而其他表却几乎不会有写入,性能没有被利用起来。出现一表有难,多表围观的场面,这种情况又叫写热点问题。写热点问题所以为了充分的利用多个分表的写入能力,tidb建议我们写入时使用随机id,这样数据就能被均匀分散到多个分片中。用户id不建议用自增id前面提到的不建议使用自增id的场景,都是技术原因导致的,而下面介绍的这个,单纯是因为业务。举个例子吧。如果你能知道一个产品每个月,新增的用户数有多少,这个对你来说会是有用的信息吗?对程序员来说,可能这个信息价值不大。但如果你是做投资的呢,或者是分析竞争对手呢?那反过来。如果你发现你的竞争对手,总能非常清晰的知道你的产品每个月新进的注册用户是多少人,你会不会心里毛毛的?如果真出现了这问题,先不要想是不是有内鬼,先检查下你的用户表主键是不是自增的。如果用户id是自增的,那别人只要每个月都注册一个新用户,然后抓包得到这个用户的user_id,然后跟上个月的值减一下,就知道这个月新进多少用户了。同样的场景有很多,有时候你去小店吃饭,发票上就写了你是今天的第几单,那大概就能估计今天店家做了多少单。你是店家,你心里也不舒服吧。再比如说一些小app的商品订单id,如果也做成自增的,那就很容易可以知道这个月成了多少单。类似的事情有很多,这些场景都建议使用趋势递增的uuid作为主键。当然,主键保持自增,但是不暴露给前端,那也行,那前面的话,你当我没说过。总结建表sql里主键边上的AUTO_INCREMENT,可以让主键自增,去掉它是可以的,但这就需要你在insert的时候自己设置主键的值。建表sql里的 PRIMARY KEY 是用来声明主键的,如果去掉,那也能建表成功,但mysql内部会给你偷偷建一个 ROW_ID的隐藏列作为主键。由于mysql使用B+树索引,叶子节点是从小到大排序的,如果使用自增id做主键,这样每次数据都加在B+树的最后,比起每次加在B+树中间的方式,加在最后可以有效减少页分裂的问题。在分库分表的场景下,我们可以通过redis等第三方组件来获得严格自增的主键id。如果不想依赖redis,可以参考雪花算法进行魔改,既能保证数据趋势递增,也能很好的满足分库分表的动态扩容。并不是所有数据库都建议使用自增id作为主键,比如tidb就推荐使用随机id,这样可以有效避免写热点的问题。而对于一些敏感数据,比如用户id,订单id等,如果使用自增id作为主键的话,外部通过抓包,很容易可以知道新进用户量,成单量这些信息,所以需要谨慎考虑是否继续使用自增主键。
0
0 676天前
1033

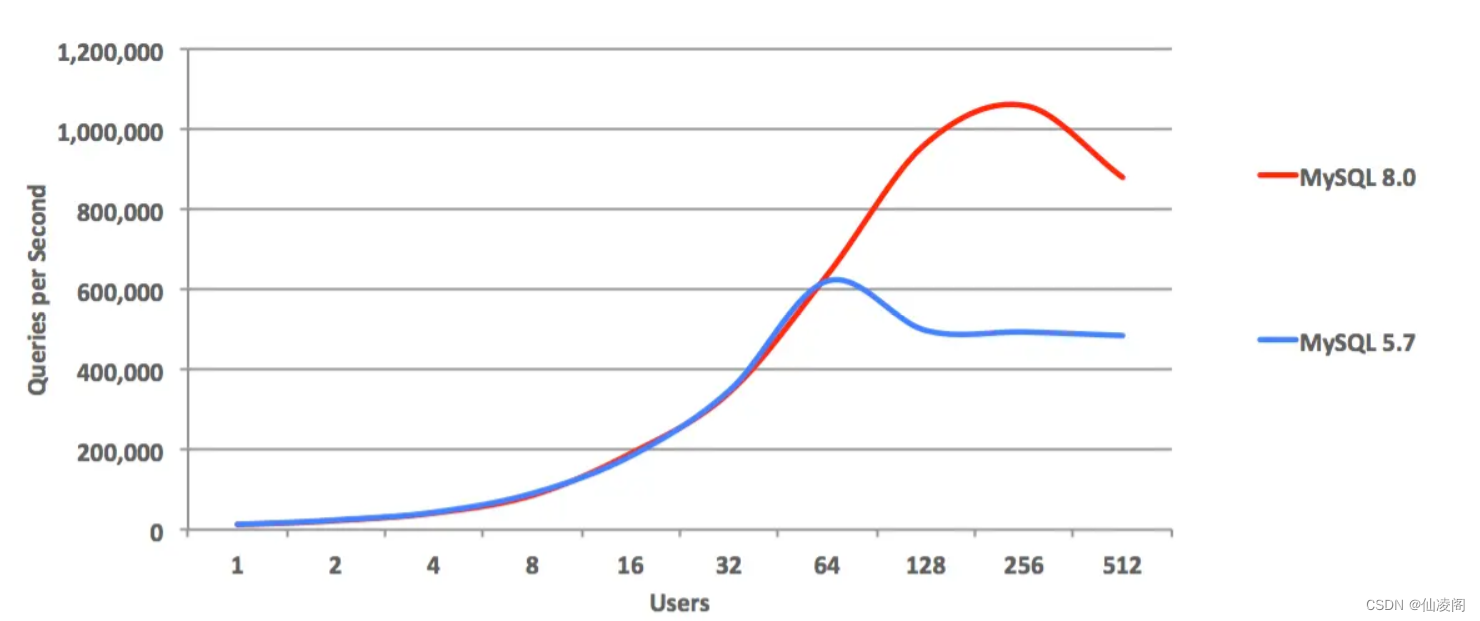
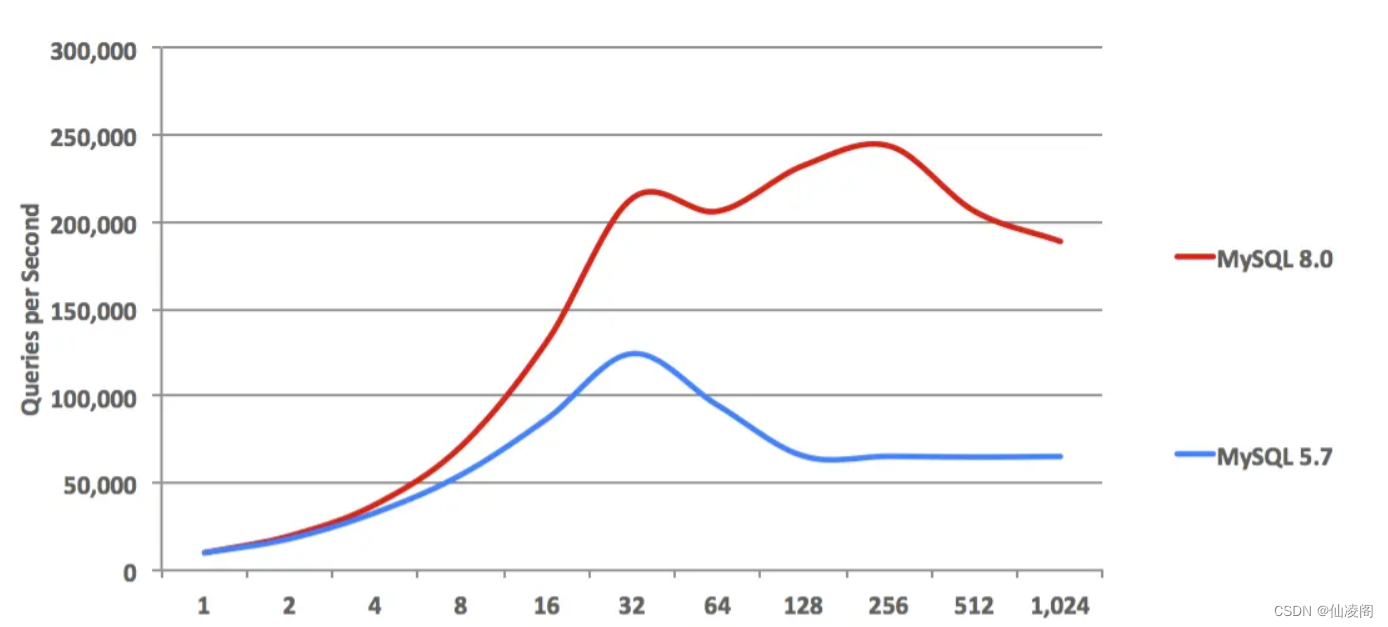
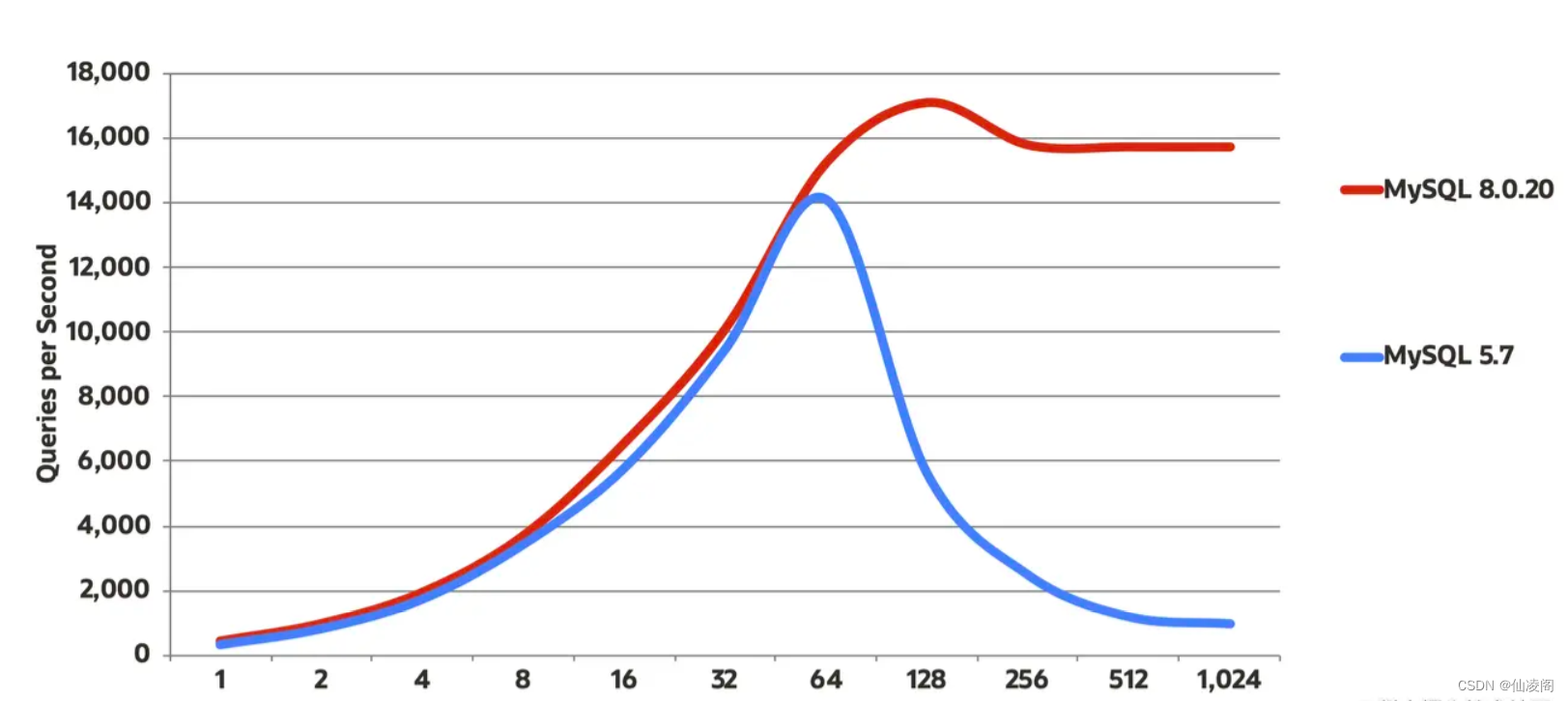
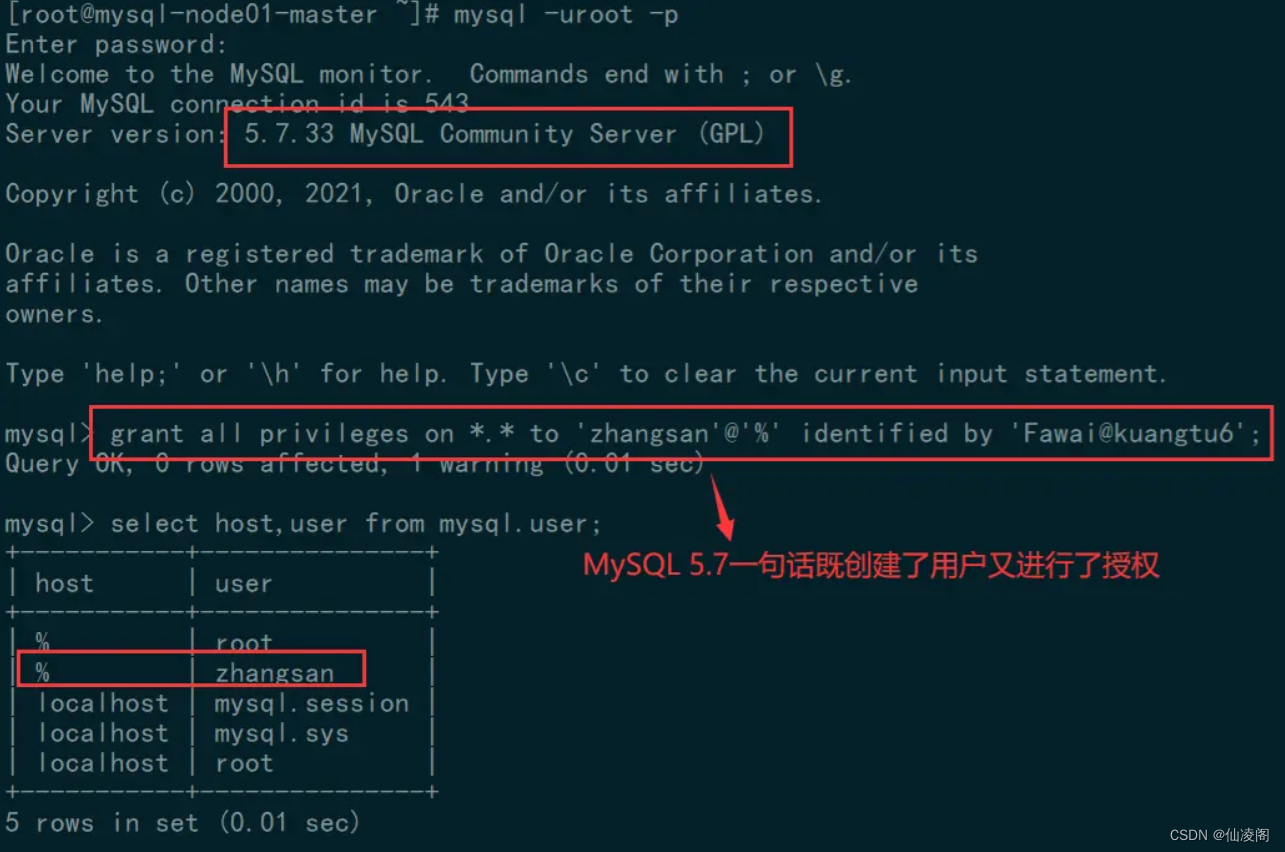
MySQL 8新特性选择MySQL 8的背景:MySQL 5.6已经停止版本更新了,对于 MySQL 5.7 版本,其将于 2023年 10月31日 停止支持。后续官方将不再进行后续的代码维护。另外,MySQL 8.0 全内存访问可以轻易跑到 200W QPS,I/O 极端高负载场景跑到 16W QPS,如下图:上面三个图来自于MySQL官网:www.mysql.com/why-mysql/b…除了高性能之外,MySQL 8还新增了很多功能,我找了几个比较有特点的新特性,在这里总结一下。本文使用的MySQL版本为 8.0.29账户与安全用户的创建和授权在MySQL之前的版本,创建用户和给创建的用户授权可以一条语句执行完成:grant all privileges on . to ‘zhangsan’@‘%’ identified by ‘Fawai@kuangtu6’;复制代码
在MySQL 8中,创建用户和授权需要分开执行,否则会报错,执行不成功:在 MySQL 8 中,需要分2不完成创建用户和授权的操作:-- 创建用户
create user 'zhangsan'@'%' identified by 'Fawai@kuangtu6';
-- 授权
grant all privileges on *.* to 'zhangsan'@'%';
复制代码
再执行创建用户时,出现了如下错误:这是因为我的 MySQL 8 安装完成后,进入命令行用的还是临时密码,并未修改root的初始密码,需要修改密码才允许操作。修改密码操作:-- 修改root密码
alter user user() identified by 'Root@001';
复制代码
再创建用户即可:mysql> create user 'zhangsan'@'%' identified by 'Fawai@kuangtu6';
Query OK, 0 rows affected (0.01 sec)
mysql> grant all privileges on *.* to 'zhangsan'@'%';
Query OK, 0 rows affected (0.00 sec)
复制代码
认证插件在MySQL中,可以用 show variables 命令查看一些设置的MySQL变量,其中密码认证插件的变量名称是 default_authentication_plugin 。MySQL 5.7版本 :mysql> show variables like ‘%default_authentication%’;±------------------------------±----------------------+| Variable_name | Value |±------------------------------±----------------------+| default_authentication_plugin | mysql_native_password |±------------------------------±----------------------+1 row in set (0.02 sec)复制代码MySQL 8版本 :mysql> show variables like ‘%default_authentication%’;±------------------------------±----------------------+| Variable_name | Value |±------------------------------±----------------------+| default_authentication_plugin | caching_sha2_password |±------------------------------±----------------------+1 row in set (0.07 sec)复制代码可以看出,5.7 版本的默认认证插件是 mysql_native_password , 而 8.0 版本的默认认证插件是 caching_sha2_password 。caching_sha2_password 这个认证插件带来的问题是,我们直接在客户端连接MySQL会连不上,比如用Navicat :我们可以临时修改一下认证插件为 mysql_native_password ,再看一下是否能连接上,修改命令为:mysql> alter user 'zhangsan'@'%' identified with mysql_native_password by 'Fawai@kuangtu6';
复制代码
此时,我们来看一下 user 表中的插件信息:zhangsan用户的认证插件改为了mysql_native_password ,而其他的认证插件仍为默认的 caching_sha2_password 。当然,alter user 修改插件的方式只能作为临时修改,而要永久修改,则需要修改MySQL配置文件 /etc/my.cnf 中的配置:然后重启MySQL服务即可。密码管理MySQL 8增加了密码管理功能,开始允许限制重复使用以前的密码:这里有几个属性,其中:password_history :此变量定义全局策略,表示在修改密码时,密码可以重复使用之前密码的更改次数。如果值为 0(默认值),则没有基于密码更改次数的重用限制。eg:值为2,表示修改密码不能和最近2次一致。password_require_current :此变量定义全局策略,用于控制尝试更改帐户密码是否必须指定要替换的当前密码。意思就是是否需要校验旧密码(off 不校验、 on校验)(针对非root用户)。password_reuse_interval :对于以前使用的帐户密码,此变量表示密码可以重复使用之前必须经过的天数。如果值为 0(默认值),则没有基于已用时间的重用限制。修改 password_history 全局策略:-- 修改密码不能和最近2次一致
set persist password_history=2;
复制代码
而如果要修改用户级别的 password_history ,命令为:alter user 'zhangsan'@'%' password history 2;
复制代码
下面来修改一下密码试试。– zhangsan的原密码是Fawai@kuangtu6,执行修改密码操作,仍修改密码为Fawai@kuangtu6,根据密码策略不允许与最近2次的密码相同,应该修改不成功alter user 'zhangsan'@'%' identified by 'Fawai@kuangtu6';
复制代码
如果把全局参数 password_history 改为0,则对于root用户就没有此限制了:索引增强MySQL 8 对索引也有相应的增强,增加了方便测试的 隐藏索引 ,真正的 降序索引 ,还增加了 函数索引。隐藏索引MySQL 8开始支持隐藏索引 (invisible index),也叫不可见索引。隐藏索引不会被优化器使用,但仍然需要进行维护-创建、删除等。其常见应用场景有:软删除、灰度发布。软删除:就是我们在线上会经常删除和创建索引,以前的版本,我们如果删除了索引,后面发现删错了,我又需要创建一个索引,这样做的话就非常影响性能。在MySQL 8中我们可以这么操作,把一个索引变成隐藏索引(索引就不可用了,查询优化器也用不上),最后确定要进行删除这个索引我们才会进行删除索引操作。灰度发布:也是类似的,我们想在线上进行一些测试,可以先创建一个隐藏索引,不会影响当前的生产环境,然后我们通过一些附加的测试,发现这个索引没问题,那么就直接把这个索引改成正式的索引,让线上环境生效。有了 隐藏索引 ,大大方便了我们做测试,可以说是非常的体贴了!下面举个例子看看隐藏索引怎么用法。创建一个表 t_test ,并创建一个正常的索引 idx_name ,一个隐藏索引 idx_age :create table t_test(id int, name varchar(20), age int);create index idx_name on t_test(name);create index idx_age on t_test(age) invisible;复制代码此时,看一下索引信息:mysql> show index from t_test\G
*************************** 1. row ***************************
Table: t_test
Non_unique: 1
Key_name: idx_name
Seq_in_index: 1
Column_name: name
Collation: A
Cardinality: 0
Sub_part: NULL
Packed: NULL
Null: YES
Index_type: BTREE
Comment:
Index_comment:
Visible: YES
Expression: NULL
*************************** 2. row ***************************
Table: t_test
Non_unique: 1
Key_name: idx_age
Seq_in_index: 1
Column_name: age
Collation: A
Cardinality: 0
Sub_part: NULL
Packed: NULL
Null: YES
Index_type: BTREE
Comment:
Index_comment:
Visible: NO
Expression: NULL
2 rows in set (0.01 sec)
复制代码
普通索引的 Visible 属性值为OFF,隐藏索引为ON。再来看一下MySQL优化器怎么处理这两种索引的:可以看到,隐藏索引在查询的时候并不会用到,就跟没有这个索引一样,那么 隐藏索引 的用处到底是个什么玩意呢?这里可以通过优化器的开关–optimizer_switch ,mysql> select @@optimizer_switch\G
*************************** 1. row ***************************
@@optimizer_switch: index_merge=on,index_merge_union=on,index_merge_sort_union=on,index_merge_intersection=on,engine_condition_pushdown=on,index_condition_pushdown=on,mrr=on,mrr_cost_based=on,block_nested_loop=on,batched_key_access=off,materialization=on,semijoin=on,loosescan=on,firstmatch=on,duplicateweedout=on,subquery_materialization_cost_based=on,use_index_extensions=on,condition_fanout_filter=on,derived_merge=on,use_invisible_indexes=off,skip_scan=on,hash_join=on,subquery_to_derived=off,prefer_ordering_index=on,hypergraph_optimizer=off,derived_condition_pushdown=on
复制代码
看到 use_invisible_indexes 配置默认是 OFF 的,将其打开看看效果:– 在会话级别设置查询优化器可以看到隐藏索引set session optimizer_switch="use_invisible_indexes=on";
复制代码
再来看一下隐藏索引 idx_age 是否生效:666!!!这样的话就方便我们项目做灰度发布了,项目上线前,我想测试一下添加的新索引是否有用,可以现将其设置为隐藏索引,这样不会影响线上业务,在会话级别将隐藏索引打开进行测试,发现没有问题后转为可见索引。可见索引与隐藏索引转换的SQL语句:-- 转换成可见索引
alter table t_test alter index idx_age visible;
-- 转换成隐藏索引
alter table t_test alter index idx_age invisible;
复制代码
降序索引MySQL 8支持 降序索引 :DESC在索引中定义不再被忽略,而是导致键值以降序存储。以前,可以以相反的顺序扫描索引,但会降低性能。降序索引可以按正序扫描,效率更高。当最有效的扫描顺序混合了某些列的升序和其他列的降序时,降序索引还使优化器可以使用多列索引。举个例子,在 MySQL 8 和 MySQL 5.7 中均执行如下建表语句:CREATE TABLE t (
c1 INT, c2 INT,
INDEX idx1 (c1 ASC, c2 ASC),
INDEX idx2 (c1 ASC, c2 DESC),
INDEX idx3 (c1 DESC, c2 ASC),
INDEX idx4 (c1 DESC, c2 DESC)
);
复制代码
然后看一下表的索引信息:具体的用处在哪里呢?插入一些数据看一下。insert into t(c1, c2) values (1, 10),(2, 20),(3, 30),(4, 40),(5, 50);
复制代码
函数索引在之前的MySQL版本中,查询时对索引进行函数操作,则该索引不生效,基于此,MySQL 8中引入了 函数索引 。还是举个简单的例子看一下:创建一个表t2,字段c1上建普通索引,字段c2上建upper函数(将字母转成大写的函数)索引。create table t2(c1 varchar(10), c2 varchar(10));
create index idx_c1 on t2(c1);
create index idx_c2 on t2((upper(c2)));
复制代码
通过show index from t2\G 看一下:下面来分别查询一下,看看索引的使用情况:由于c1字段上是普通索引,使用upper(c1)查询时并没有用到索引优化,而c2字段上有函数索引upper(c2),可以把整个upper(c2)看成是一个索引字段,查询时索引生效了!函数索引的实现原理:函数索引在MySQL中相当于新增了一个列,这个列会根据函数来进行计算结果,然后使用函数索引的时候就会用这个计算后的列作为索引,其实就是增加了一个虚拟的列,然后根据虚拟的列进行查询,从而达到利用索引的目的。原子DDL操作MySQL 8.0 支持原子数据定义语言 (DDL) 语句。此功能称为原子 DDL。原子 DDL 语句将与 DDL 操作关联的数据字典更新、存储引擎操作和二进制日志写入组合到单个原子操作中。操作要么被提交,适用的更改被持久化到数据字典、存储引擎和二进制日志中,要么被回滚,即使服务器在操作期间停止。举个简单的例子:数据库中有表t1,没有表t2,执行语句删除t1和t2。mysql> create table t1(c1 int);
Query OK, 0 rows affected (0.04 sec)
mysql> show tables;
+----------------+
| Tables_in_test |
+----------------+
| t1 |
+----------------+
1 row in set (0.00 sec)
mysql> drop table t1,t2;
ERROR 1051 (42S02): Unknown table 'test.t2'
mysql> show tables;
+----------------+
| Tables_in_test |
+----------------+
| t1 |
+----------------+
1 row in set (0.00 sec)
复制代码
上面是在 MySQL 8 中的操作,可以看到该操作并没有删除掉表t1,那么在之前的版本呢,下面在 MySQL 5.7 版本中进行同样的操作:mysql> create table t1(c1 int);
Query OK, 0 rows affected (0.06 sec)
mysql> show tables;
+----------------+
| Tables_in_test |
+----------------+
| t1 |
+----------------+
1 row in set (0.00 sec)
mysql> drop table t1,t2;
ERROR 1051 (42S02): Unknown table 'test.t2'
mysql> show tables;
Empty set (0.00 sec)
复制代码
虽然也有报错提示说t2表不存在,但是t1表是真实的被删除掉了!TIPS:如果确需要执行drop表操作,请使用 if exists 来防止删除不存在的表时出现的错误。一个原子 DDL 操作内容包括:更新数据字典存储引擎层的操作在 binlog 中记录 DDL 操作支持与表相关的 DDL:数据库表空间表索引的 CREATE、ALTER、DROP 以及 TRUNCATE TABLE支持的其他 DDL :存储程序、触发器、视图、UDF 的 CREATE、DROP 以及ALTER 语句。支持账户管理相关的 DDL:用户和角色的 CREATE、ALTER、DROP 以及适用的 RENAME,以及 GRANT 和 REVOKE 语句。通用表达式(CTE)Common Table Expressions(CTE)通用表达式,也就是MySQL 8中的 with 语句。通过一个简单的例子了解一下。idx展示1~10行,可以直接select 1 union select 2 …select 10这样:select 1 as idx
UNION
select 2 as idx
UNION
select 3 as idx
UNION
select 4 as idx
UNION
select 5 as idx
UNION
select 6 as idx
UNION
select 7 as idx
UNION
select 8 as idx
UNION
select 9 as idx
UNION
select 10 as idx;
复制代码
通过CTE表达式,可以用递归的方式简化为如下写法:with recursive cte(idx) as
(
select 1
UNION
select idx+1 from cte where idx<10
)
select * from cte;
复制代码
再比如,有这样一个场景,查看某个员工的上下级关系,就可以通过CTE递归查出来。其他MySQL 8 还有很多比较实用的新特性,比如 :Window Function,对于查询中的每一行,使用与该行相关的行执行计算。JSON增强InnoDB 其他改进功能 ,比如死锁检查控制 innodb_deadlock_detect,对于高并发的系统,禁用死锁检查可能带来性能的提高。这里不多做举例了(有没有一种可能是作者太懒?),官方文档上面那是相当的详细!源码附件已经打包好上传到百度云了,大家自行下载即可~链接: https://pan.baidu.com/s/14G-bpVthImHD4eosZUNSFA?pwd=yu27提取码: yu27百度云链接不稳定,随时可能会失效,大家抓紧保存哈。如果百度云链接失效了的话,请留言告诉我,我看到后会及时更新~开源地址码云地址:http://github.crmeb.net/u/defuGithub 地址:http://github.crmeb.net/u/defu开源不易,Star 以表尊重,感兴趣的朋友欢迎 Star,提交 PR,一起维护开源项目,造福更多人!原文链接:https://juejin.cn/post/7111255789876019208
0
0 676天前
870
123456一.请简述MySQL配置文件的加载顺序?二.MySQL启动时如果找不到配置(参数)文件,会报错还是启动?三.如何查看MySQL参数?四.如何修改MySQL参数?五:MySQL有哪些类型表空间,简述各自作用?六:请简述MySQL redo log和binlog区别? 一.请简述MySQL配置文件的加载顺序?MySQL读取配置文件的顺序读取顺序:/etc/mysql/my.cnf>/etc/my.cnf>~/.my.cnf 命令验证:方法1:123456[mysql@mysql01 bin]$ mysql --help|grep my.cnf/etc/mysql/my.cnf /etc/my.cnf ~/.my.cnf order of preference, my.cnf, $MYSQL_TCP_PORT,[mysql@mysql01 bin]$ mysql --verbose --help | grep my.cnf/etc/mysql/my.cnf /etc/my.cnf ~/.my.cnf order of preference, my.cnf, $MYSQL_TCP_PORT,方法2: 1234[mysql@mysql01 bin]$ my_print_defaults --help|grep -A2 -B2 my.cnfDefault options are read from the following files in the given order:/etc/mysql/my.cnf /etc/my.cnf ~/.my.cnf Variables (--variable-name=value)二.MySQL启动时如果找不到参数文件,会报错还是启动?MySQL数据库参数文件的作用和Oracle数据库的参数文件极其类似,不同的是,Oracle实例在启动时若找不到参数文件,是不能进行装载(mount)操作。MySQL稍微有所不同,MySQL实例可以不需要参数文件,这时所有的参数值取决于编译MySQL时指定的默认值和源代码中指定参数的默认值。如果MySQL实例在默认的数据库目录下找不到mysql架构,则启动同样会失败。三.如何查看MySQL参数?可以把数据库参数看成一个键/值(key/value)对。可以通过命令SHOW VARIABLES查看数据库中的所有参数,也可以通过LIKE来过滤参数名。从MySQL 5.1版本开始,还可以通过information_schema架构下的GLOBAL_VARIABLES视图来进行查找。12345show variables like '%timeout%';mysql> SHOW [{GLOBAL|SESSION}] VARIABLES [LIKE ''];mysql> SELECT @@{GLOBAL|SESSION}.VARIABLE_NAME;mysql> SELECT * FROM INFORMATION_SCHEMA.GLOBAL_VARIABLES WHERE VARIABLE_NAME='VARIABLE_NAME';mysql> SELECT * FROM INFORMATION_SCHEMA.SESSION_VARIABLES WHERE VARIABLE_NAME='VARIABLE_NAME';通过配置文件查看参数cat /etc/my.cnf|grep -i "VARIABLE_NAME"四.如何修改MySQL参数?会话级别修改:set session innodb_lock_wait_timeout=50;对当前会话立即生效,退出后,参数失效,不影响后续的会话全局级别修改:set global innodb_lock_wait_timeout=50;当前会话不生效,对后续连接进来的会话生效修改配置文件五:MySQL有哪些类型表空间,简述各自作用?MySQL有五种表空间: 系统表空间(也叫共享表空间) 、独立表空间 、临时表空间 、undo表空间 、通用表空间。1.系统表空间主要用来存放undo信息、insert buffer 索引页、double write buffer 等数据。系统表空间系统表空间(system tablespace)是在初始化mysql实例时生成的,读取my.cnf中的innodb_data_file_path参数,初始对应大小的文件。mysql默认的系统表空间文件大小是12M,只有一个文件(ibdata1),它默认是保存在mysql实例的datadir变量的目录下。#### 在mysql实例中查看共享表空间的大小1234567MySQL [cjcdb]> select @@global.innodb_data_file_path;+--------------------------------+| @@global.innodb_data_file_path |+--------------------------------+| ibdata1:12M:autoextend | # 共享表空间的文件是ibdata1,大小是12M+--------------------------------+ # autoextend自动扩展1 row in set (0.00 sec)#### 在mysql的datadir变量所指定的目录下查看系统表空间文件1234567MySQL [cjcdb]> select @@global.datadir;+------------------------+| @@global.datadir |+------------------------+| /usr/local/mysql/data/ |+------------------------+1 row in set (0.00 sec)当系统表空间不够用时(也就是ibdata1文件),会自动扩展(autoextend),默认每次自动扩展64M。1234567MySQL [cjcdb]> select @@innodb_autoextend_increment;+-------------------------------+| @@innodb_autoextend_increment |+-------------------------------+| 64 |+-------------------------------+1 row in set (0.00 sec)2.独立表空间从mysql 5.6.6版本开始,独立表空间(file-per-table tablespaces)默认是开启的(也就是innodb_file_per_table参数不设置时,默认等于1),在开启的情况下,创建一个innodb引擎的表,那么表有自己独立的一些数据文件。这些数据文件在操作系统上的文件体现如下所示:表名.frm # 表的表结构文件(里面存放的是表的创建语句)表名.ibd # 表的数据文件(当有数据往表中插入时,数据就保存之个文件中的)独立表空间的好处:01:表数据分开存放(不把所有鸡蛋放在1个蓝子里面);损坏1个文件不至于影响所有表02:容易维护,查询速度快(IO分散)03:使用MySQL Enterprise Backup快速备份或还原在每表文件表空间中创建的表,不会中断其他InnoDB 表的使用缺点:对fsync系统调用来说不友好,如果使用一个表空间文件的话单次系统调用可以完成数据的落盘,但是如果你将表空间文件拆分成多个。原来的一次fsync可能会就变成针对涉及到的所有表空间文件分别执行一次fsync,增加fsync的次数。独立表空间文件中仅存放该表对应数据、索引、insert buffer bitmap。其余的诸如:undo信息、insert buffer 索引页、double write buffer 等信息依然放在默认表空间,也就是共享表空间中。当innodb_file_per_table参数为0时,表示使用系统表空间,当为1时,表示使用独立表空间。innodb_file_per_table选项只对新建的表起作用,对于已经分配了表空间的表不起作用。如果想把已经分配到系统表空间中的表转移到独立表空间,可以使用下面语句:ALTER TABLE 表名 TABLESPACE [=] innodb_file_per_tables;如果要将已经存储在独立表空间的表转移到系统表空间:ALTER TABLE 表名 TABLESPACE [=] innodb_system;其中中括号里的=可有可无。与InnoDB不同,MyISAM并没有什么表空间一说,表的数据和索引都存放在对应的数据库子目录下。假如cjc表使用的是MyISAM存储引擎,那么他所在数据库对应的目录下会为cjc表创建下面3个文件:1.cjc.frm 表结构。2.cjc.MYD 表数据。3.cjc.MYI 表索引。3.临时表空间临时表空间用于存放用户创建的临时表和磁盘内部临时表。参数innodb_temp_data_file_path定义了临时表空间的一些名称、大小、规格属性1234567MySQL [cjcdb]> show variables like '%innodb_temp_data_file_path%';+----------------------------+-----------------------+| Variable_name | Value |+----------------------------+-----------------------+| innodb_temp_data_file_path | ibtmp1:12M:autoextend |+----------------------------+-----------------------+1 row in set (0.00 sec)MySQL 5.7对于InnoDB存储引擎的临时表空间做了优化。在MySQL 5.7之前,INNODB引擎的临时表都保存在ibdata里面,而ibdata的贪婪式磁盘占用导致临时表的创建与删除对其他正常表产生非常大的性能影响。在MySQL5.7中,对于临时表做了下面两个重要方面的优化:(1)MySQL 5.7 把临时表的数据以及回滚信息(仅限于未压缩表)从共享表空间里面剥离出来,形成自己单独的表空间,参数为innodb_temp_data_file_path。(2)MySQL 5.7 把临时表的相关检索信息保存在系统信息表中:information_schema.innodb_temp_table_info. 而MySQL 5.7之前的版本想要查看临时表的系统信息是没有太好的办法。select * frominformation_schema.innodb_temp_table_info;需要注意的一点就是:虽然INNODB临时表有自己的表空间,但是目前还不能自己定义临时表空间文件的保存路径,只能是继承innodb_data_home_dir。此时如果想要拿其他的磁盘,比如内存盘来充当临时表空间的保存地址,只能用老办法,做软链。MySQL临时表类型1.外部临时表,通过create temporary table语法创建的临时表,可以指定存储引擎为memory,innodb, myisam等等,这类表在会话结束后,会被自动清理。如果临时表与非临时表同时存在,那么非临时表不可见。show tables命令不显示临时表信息。可通过informationschema.INNODBTEMPTABLEINFO系统表可以查看外部临时表的相关信息2.内部临时表,通常在执行复杂SQL,比如group by, order by, distinct, union等,执行计划中如果包含Using temporary.还有undo回滚的时候,但空间不足的时候,MySQL内部将使用自动生成的临时表,以辅助完成工作。外部临时表、内部临时表参数tmp_table_size内部临时表在内存中的的最大值,与max_heap_table_size参数共同决定,取二者的最小值。如果临时表超过该值,就会从内存转移到磁盘上;max_heap_table_size用户创建的内存表的最大值,也用于和tmp_table_size一起,限制内部临时表在内存中的大小;innodb_tmpdirinnodb_temp_data_file_pathinnodb引擎下temp文件属性。建议限制innodbtempdatafilepath = ibtmp1:1G:autoextend:max:30G;default_tmp_storage_engine外部临时表(create temporary table创建的表)默认的存储引擎;internal_tmp_disk_storage_engine磁盘上的内部临时表存储引擎,可选值为myisam或者innodb。使用innodb表在某些场景下,比如临时表列太多,或者行大小超过限制,可能会出现“ Row size too large or Too many columns”的错误,这时应该将临时表的innodb引擎改回myisam。slave_load_tmpdirtmpdir表示磁盘上临时表所在的目录。临时表目录,当临时表大小超过一定阈值,就会从内存转移到磁盘上;max_tmp_tables状态信息Created_tmp_disk_tables执行SQL语句时,MySQL在磁盘上创建的内部临时表数量,如果这个值很大,可能原因是分配给临时表的最大内存值较小,或者SQL中有大量排序、分组、去重等操作,SQL需要优化;Created_tmp_files创建的临时表数量;Created_tmp_tables执行SQL语句时,MySQL创建的内部临时表数量;Slave_open_temp_tablesstatement 或则 mix模式下才会看到有使用;通过复制,当前slave创建了多少临时表information_schema.innodb_temp_table_info4.undo表空间MySQL5.5时代的undo log在MySQL5.5以及之前,InnoDB的undo log也是存放在ibdata1里面的。一旦出现大事务,这个大事务所使用的undo log占用的空间就会一直在ibdata1里面存在,即使这个事务已经关闭。答案是没有直接的办法,只能全库导出sql文件,然后重新初始化mysql实例,再全库导入。MySQL 5.6时代的undo logMySQL 5.6增加了参数innodb_undo_directory、innodb_undo_logs和innodb_undo_tablespaces这3个参数,可以把undo log从ibdata1移出来单独存放。innodb_undo_directory,指定单独存放undo表空间的目录,默认为.(即datadir),可以设置相对路径或者绝对路径。该参数实例初始化之后虽然不可直接改动,但是可以通过先停库,修改配置文件,然后移动undo表空间文件的方式去修改该参数;innodb_undo_tablespaces,指定单独存放的undo表空间个数,例如如果设置为3,则undo表空间为undo001、undo002、undo003,每个文件初始大小默认为10M。该参数我们推荐设置为大于等于3,原因下文将解释。该参数实例初始化之后不可改动;innodb_undo_logs,指定回滚段的个数(早期版本该参数名字是innodb_rollback_segments),默认128个。每个回滚段可同时支持1024个在线事务。这些回滚段会平均分布到各个undo表空间中。该变量可以动态调整,但是物理上的回滚段不会减少,只是会控制用到的回滚段的个数。实际使用方面,在初始化实例之前,我们只需要设置innodb_undo_tablespaces参数(建议大于等于3)即可将undo log设置到单独的undo表空间中。MySQL 5.7时代的undo logMySQL 5.7引入了新的参数,innodb_undo_log_truncate,开启后可在线收缩拆分出来的undo表空间。在满足以下2个条件下,undo表空间文件可在线收缩:innodb_undo_tablespaces>=2。因为truncate undo表空间时,该文件处于inactive状态,如果只有1个undo表空间,那么整个系统在此过程中将处于不可用状态。为了尽可能降低truncate对系统的影响,建议将该参数最少设置为3;innodb_undo_logs>=35(默认128)。因为在MySQL 5.7中,第一个undo log永远在系统表空间中,另外32个undo log分配给了临时表空间,即ibtmp1,至少还有2个undo log才能保证2个undo表空间中每个里面至少有1个undo log;满足以上2个条件后,把innodb_undo_log_truncate设置为ON即可开启undo表空间的自动truncate,这还跟如下2个参数有关:(1)innodb_max_undo_log_size,undo表空间文件超过此值即标记为可收缩,默认1G,可在线修改;(2)innodb_purge_rseg_truncate_frequency,指定purge操作被唤起多少次之后才释放rollback segments。当undo表空间里面的rollback segments被释放时,undo表空间才会被truncate。由此可见,该参数越小,undo表空间被尝试truncate的频率越高。MySQL 8.0收缩UNDO1、添加新的undo文件undo003。mysql8.0中默认innodb_undo_tablespace为2个,不足2个时,不允许设置为inactive,且默认创建的undo受保护,不允许删除。2、将膨胀的 undo 临时设置为inactive,以及 innodb_undo_log_truncate=on,自动 truncate 释放膨胀的undo空间。3、重新将释放空间之后的undo设置为active,可重新上线使用。具体操作如下:1234567891011MySQL [cjcdb]> show variables like '%undo%';+--------------------------+------------+| Variable_name | Value |+--------------------------+------------+| innodb_max_undo_log_size | 1073741824 || innodb_undo_directory | ./ || innodb_undo_log_truncate | OFF || innodb_undo_logs | 128 || innodb_undo_tablespaces | 0 |+--------------------------+------------+5 rows in set (0.00 sec)查看undo大小12mysql[(none)]> system du -sh /app/dbdata/datanode3307/log/undo*10G /app/dbdata/datanode3307/log/undo_001添加新的undo表空间undo003。系统默认是2个undo,大小设置4G123mysql[(none)]> mysql[(none)]> create undo tablespace undo001 add datafile '/usr/local/mysql/data/undo/undo001.ibu';Query OK, 0 rows affected (0.21 sec)注意:创建添加新的undo必须以.ibu结尾,否则触发如下错误提示12mysql[(none)]> create undo tablespace undo003 add datafile '/app/dbdata/datanode3307/log/undo_003.' ;ERROR 3121 (HY000): The ADD DATAFILE filepath must end with '.ibu'.5.通用表空间通用表空间(General Tablespaces)通用表空间为通过create tablespace语法创建的共享表空间。通用表空间可以创建于mysql数据目录外的其他表空间,其可以容纳多张表,且其支持所有的行格式。通过create table tab_name ... tablespace [=] tablespace_name或alter table tab_name tablespace [=] tablespace_name语法将其添加与通用表空间内。六:请简述MySQL redo log和binlog区别? redo log 和 binlog 的区别:日志归属:binlog由Server层实现,所有引擎都可以使用。redo log是innodb引擎特有的日志。日志类型:binlog是逻辑日志,记录原始SQL或数据变更前后内容。redo是物理日志,记录在哪些页上进行了哪些修改。写入方式:binlog是追加写,写满一个文件后创建新文件继续写。redo log是循环写,全部写满后覆盖从头写。适用场景:binlog适用于主从恢复和误删除恢复。redo log适用于崩溃恢复。虽然在更新BufferPool后,也写入了binlog中,但binlog并不具备crash-safe的能力。因为崩溃可能发生在写binlog后,刷脏前。在主从同步的情况下,从节点会拿到多出来的一条binlog。所以server层的binlog是不支持崩溃恢复的,只是支持误删数据恢复。InnoDB考虑到这一点,自己实现了redo log。因为最开始 MySQL 里并没有 InnoDB 引擎。MySQL 自带的引擎是 MyISAM,但是 MyISAM 没有 crash-safe 的能力,binlog 日志只能用于归档。而 InnoDB 是另一个公司以插件形式引入 MySQL 的,既然只依靠 binlog 是没有 crash-safe 能力的,所以 InnoDB 使用另外一套日志系统——也就是 redo log 来实现 crash-safe 能力。来自 “ ITPUB博客 ” ,链接:http://blog.itpub.net/29785807/viewspace-2886375/,如需转载,请注明出处,否则将追究法律责任。
0
0 680天前
986
环境说明:MySQL:5.7.34 双主OS:Redhat 7.5问题现象:XXX应用登录,提示数据库连接失败。问题原因:有一张权限表,同时执行了delete和truncate操作,并且长时间没有提交,导致metadata lock无法释放,应用登录时无法正常读取权限表,导致应用无法登录。初步怀疑应用在执行delete操作时开启了事务,并且没有及时提交,导致锁无法释放。解决方案:和应用相关同事沟通,杀掉相关会话后,恢复正常。问题重现:1.开启锁监控。1234567891011121314151617181920212223242526MySQL [cjc]> select * from performance_schema.setup_instruments where name like '%lock%' limit 20;+---------------------------------------------------------+---------+-------+| NAME | ENABLED | TIMED |+---------------------------------------------------------+---------+-------+| wait/synch/mutex/sql/TC_LOG_MMAP::LOCK_tc | NO | NO || wait/synch/mutex/sql/LOCK_des_key_file | NO | NO || wait/synch/mutex/sql/MYSQL_BIN_LOG::LOCK_commit | NO | NO || wait/synch/mutex/sql/MYSQL_BIN_LOG::LOCK_commit_queue | NO | NO || wait/synch/mutex/sql/MYSQL_BIN_LOG::LOCK_done | NO | NO || wait/synch/mutex/sql/MYSQL_BIN_LOG::LOCK_flush_queue | NO | NO || wait/synch/mutex/sql/MYSQL_BIN_LOG::LOCK_index | NO | NO || wait/synch/mutex/sql/MYSQL_BIN_LOG::LOCK_log | NO | NO || wait/synch/mutex/sql/MYSQL_BIN_LOG::LOCK_binlog_end_pos | NO | NO || wait/synch/mutex/sql/MYSQL_BIN_LOG::LOCK_sync | NO | NO || wait/synch/mutex/sql/MYSQL_BIN_LOG::LOCK_sync_queue | NO | NO || wait/synch/mutex/sql/MYSQL_BIN_LOG::LOCK_xids | NO | NO || wait/synch/mutex/sql/MYSQL_RELAY_LOG::LOCK_commit | NO | NO || wait/synch/mutex/sql/MYSQL_RELAY_LOG::LOCK_commit_queue | NO | NO || wait/synch/mutex/sql/MYSQL_RELAY_LOG::LOCK_done | NO | NO || wait/synch/mutex/sql/MYSQL_RELAY_LOG::LOCK_flush_queue | NO | NO || wait/synch/mutex/sql/MYSQL_RELAY_LOG::LOCK_index | NO | NO || wait/synch/mutex/sql/MYSQL_RELAY_LOG::LOCK_log | NO | NO || wait/synch/mutex/sql/MYSQL_RELAY_LOG::LOCK_sync | NO | NO || wait/synch/mutex/sql/MYSQL_RELAY_LOG::LOCK_sync_queue | NO | NO |+---------------------------------------------------------+---------+-------+20 rows in set (0.00 sec)开启监控123MySQL [cjc]> update performance_schema.setup_instruments set enabled = 'YES' where name like '%lock%';Query OK, 173 rows affected (0.00 sec)Rows matched: 180 Changed: 173 Warnings: 02.关闭自动提交注意:关闭自动提交的用户权限需要小于启动mysql的用户权限,否则关闭自动提交不生效,而且没有任何提示。123456789MySQL [cjc]> set autocommit=0;Query OK, 0 rows affected (0.00 sec)MySQL [cjc]> show variables like 'autocommit';+---------------+-------+| Variable_name | Value |+---------------+-------+| autocommit | OFF |+---------------+-------+1 row in set (0.00 sec)3.会话1,删除表,不提交。delete from t2;4.会话2,可以正常查询表数据。123456789MySQL [cjc]> select * from t2;+------+------+| id | age |+------+------+| 1 | 100 || 2 | 30 || 3 | 80 |+------+------+3 rows in set (0.01 sec)5.会话3,执行truncate操作,被阻塞truncate table t2;卡住6.会话2,仍然可以查询表数据。123456789MySQL [cjc]> select * from t2;+------+------+| id | age |+------+------+| 1 | 100 || 2 | 30 || 3 | 80 |+------+------+3 rows in set (0.01 sec)7.打开另一个新的会话4,无法查询数据,被阻塞MySQL [cjc]> select * from t2;卡住8.打开会话5,执行数据库备份,被阻塞。执行备份1[mysql@mysql01 backup]$ mysqldump -uroot -p cjc > /home/mysql/backup/cjc.sql卡住9.打开会话6,查询会话信息id 16,31,33都被阻塞12345678910MySQL [(none)]> select id,host,user,command,time,state,info from information_schema.processlist where command !='sleep';+----+-----------+------+---------+------+---------------------------------+---------------------------------------------------------------------------------------------------------+| id | host | user | command | time | state | info |+----+-----------+------+---------+------+---------------------------------+---------------------------------------------------------------------------------------------------------+| 34 | localhost | root | Query | 0 | executing | select id,host,user,command,time,state,info from information_schema.processlist where command !='sleep' || 31 | localhost | cjc | Query | 253 | Waiting for table metadata lock | select * from t2 || 16 | localhost | cjc | Query | 269 | Waiting for table metadata lock | truncate table t2 || 33 | localhost | root | Query | 171 | Waiting for table metadata lock | LOCK TABLES `t1` READ /*!32311 LOCAL */,`t2` READ /*!32311 LOCAL */ |+----+-----------+------+---------+------+---------------------------------+---------------------------------------------------------------------------------------------------------+4 rows in set (0.00 sec)10.查看锁阻塞源头1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859606162636465666768697071727374757677787980MySQL [(none)]> select * from performance_schema.metadata_locks where OWNER_THREAD_ID !=sys.ps_thread_id(connection_id())\G;*************************** 1. row *************************** OBJECT_TYPE: TABLE OBJECT_SCHEMA: cjc OBJECT_NAME: t2OBJECT_INSTANCE_BEGIN: 139671541629072 LOCK_TYPE: SHARED_WRITE LOCK_DURATION: TRANSACTION LOCK_STATUS: GRANTED SOURCE: OWNER_THREAD_ID: 37 OWNER_EVENT_ID: 36*************************** 2. row *************************** OBJECT_TYPE: GLOBAL OBJECT_SCHEMA: NULL OBJECT_NAME: NULLOBJECT_INSTANCE_BEGIN: 139671933907680 LOCK_TYPE: INTENTION_EXCLUSIVE LOCK_DURATION: STATEMENT LOCK_STATUS: GRANTED SOURCE: OWNER_THREAD_ID: 41 OWNER_EVENT_ID: 26*************************** 3. row *************************** OBJECT_TYPE: SCHEMA OBJECT_SCHEMA: cjc OBJECT_NAME: NULLOBJECT_INSTANCE_BEGIN: 139671933882208 LOCK_TYPE: INTENTION_EXCLUSIVE LOCK_DURATION: TRANSACTION LOCK_STATUS: GRANTED SOURCE: OWNER_THREAD_ID: 41 OWNER_EVENT_ID: 26*************************** 4. row *************************** OBJECT_TYPE: TABLE OBJECT_SCHEMA: cjc OBJECT_NAME: t2OBJECT_INSTANCE_BEGIN: 139671933942976 LOCK_TYPE: EXCLUSIVE LOCK_DURATION: TRANSACTION LOCK_STATUS: PENDING SOURCE: OWNER_THREAD_ID: 41 OWNER_EVENT_ID: 26*************************** 5. row *************************** OBJECT_TYPE: TABLE OBJECT_SCHEMA: cjc OBJECT_NAME: t2OBJECT_INSTANCE_BEGIN: 139671799800656 LOCK_TYPE: SHARED_READ LOCK_DURATION: TRANSACTION LOCK_STATUS: PENDING SOURCE: OWNER_THREAD_ID: 56 OWNER_EVENT_ID: 9*************************** 6. row *************************** OBJECT_TYPE: TABLE OBJECT_SCHEMA: cjc OBJECT_NAME: t1OBJECT_INSTANCE_BEGIN: 139672135191008 LOCK_TYPE: SHARED_READ LOCK_DURATION: TRANSACTION LOCK_STATUS: GRANTED SOURCE: OWNER_THREAD_ID: 58 OWNER_EVENT_ID: 10*************************** 7. row *************************** OBJECT_TYPE: TABLE OBJECT_SCHEMA: cjc OBJECT_NAME: t2OBJECT_INSTANCE_BEGIN: 139672135191104 LOCK_TYPE: SHARED_READ LOCK_DURATION: TRANSACTION LOCK_STATUS: PENDING SOURCE: OWNER_THREAD_ID: 58 OWNER_EVENT_ID: 107 rows in set (0.10 sec)ERROR: No query specifiedMySQL [(none)]> select THREAD_ID,PROCESSLIST_ID,name,type from performance_schema.threads where PROCESSLIST_ID is not NULL;123456789101112+-----------+----------------+--------------------------------+------------+| THREAD_ID | PROCESSLIST_ID | name | type |+-----------+----------------+--------------------------------+------------+| 28 | 3 | thread/sql/compress_gtid_table | FOREGROUND || 37 | 12 | thread/sql/one_connection | FOREGROUND || 41 | 16 | thread/sql/one_connection | FOREGROUND || 56 | 31 | thread/sql/one_connection | FOREGROUND || 57 | 32 | thread/sql/one_connection | FOREGROUND || 58 | 33 | thread/sql/one_connection | FOREGROUND || 59 | 34 | thread/sql/one_connection | FOREGROUND |+-----------+----------------+--------------------------------+------------+7 rows in set (0.00 sec可以看到阻塞源头是THREAD_ID=37 PROCESSLIST_ID=1212| 37 | 12 | thread/sql/one_connection | FOREGROUND |select * from performance_schema.events_statements_current where thread_id=37\G;查看最后一次执行的命令123456789101112131415161718192021222324252627282930313233343536373839404142434445MySQL [(none)]> select * from performance_schema.events_statements_current where thread_id=37\G;*************************** 1. row *************************** THREAD_ID: 37 EVENT_ID: 35 END_EVENT_ID: 35 EVENT_NAME: statement/sql/delete SOURCE: TIMER_START: 6409813713486000 TIMER_END: 6409813929865000 TIMER_WAIT: 216379000 LOCK_TIME: 64000000 SQL_TEXT: delete from t2 DIGEST: 3ba93c5fbd4c5721001bc1856c74459a DIGEST_TEXT: DELETE FROM `t2` CURRENT_SCHEMA: cjc OBJECT_TYPE: NULL OBJECT_SCHEMA: NULL OBJECT_NAME: NULL OBJECT_INSTANCE_BEGIN: NULL MYSQL_ERRNO: 0 RETURNED_SQLSTATE: 00000 MESSAGE_TEXT: NULL ERRORS: 0 WARNINGS: 0 ROWS_AFFECTED: 3 ROWS_SENT: 0 ROWS_EXAMINED: 3CREATED_TMP_DISK_TABLES: 0 CREATED_TMP_TABLES: 0 SELECT_FULL_JOIN: 0 SELECT_FULL_RANGE_JOIN: 0 SELECT_RANGE: 0 SELECT_RANGE_CHECK: 0 SELECT_SCAN: 0 SORT_MERGE_PASSES: 0 SORT_RANGE: 0 SORT_ROWS: 0 SORT_SCAN: 0 NO_INDEX_USED: 0 NO_GOOD_INDEX_USED: 0 NESTING_EVENT_ID: NULL NESTING_EVENT_TYPE: NULL NESTING_EVENT_LEVEL: 01 row in set (0.00 sec)ERROR: No query specified在刚刚执行delete操作的窗口查询,确实是12。1234567MySQL [cjc]> select connection_id();+-----------------+| connection_id() |+-----------------+| 12 |+-----------------+1 row in set (0.00 sec)11.终止12会话MySQL [(none)]> kill 12;Query OK, 0 rows affected (0.00 sec)12.验证查询t2数据已经被清空MySQL [(none)]> select * from cjc.t2;Empty set (0.00 sec)锁已释放MySQL [(none)]> select id,host,user,command,time,state,info from information_schema.processlist where command !='sleep' and user !='root';来自 “ ITPUB博客 ” ,链接:http://blog.itpub.net/29785807/viewspace-2900124/
0
0 680天前

